L’étude des données et l’utilisation de modèles stochastiques permettent de transformer des informations brutes en prévisions structurées, en s’appuyant sur des méthodes statistiques et des principes probabilistes solides. Dans le cadre des sciences sociales computationnelles, ces techniques servent à décrypter des comportements humains complexes en examinant les écarts et les variations au sein de systèmes qui semblent parfois chaotiques.
À titre d’exemple, suivre les probabilités dans un environnement contrôlé comme un ile de france casino constitue un terrain d’expérimentation captivant, où les concepts mathématiques se confrontent directement à l’aléatoire. Que ce soit pour la finance ou pour les jeux, ces modèles reposent tous sur des logiques communes de gestion des risques et d’analyse comportementale.
Bases de la probabilité et incertitude algorithmique
La modélisation stochastique s’intéresse aux systèmes dont l’évolution dépend en partie du hasard, rendant l’avenir probabiliste plutôt que strictement prévisible. Comprendre ces principes est indispensable pour quiconque souhaite travailler en intelligence artificielle ou en recherche opérationnelle. Il est remarquable de voir que les travaux de Pascal et Fermat au XVIIᵉ siècle restent pertinents. Leur réflexion sur le « problème des partis », issu des jeux de hasard, a jeté les fondations de la théorie moderne des probabilités.
Aujourd’hui, entraîner un modèle de machine learning revient à manipuler des distributions probabilistes conditionnelles. La fonction de perte (loss function) mesure l’incertitude que l’on cherche à réduire. L’un des défis principaux consiste à séparer le signal du bruit : dans de très larges ensembles de données, les fluctuations aléatoires peuvent être interprétées à tort comme des tendances, menant au surapprentissage, ou overfitting.
Les chaînes de Markov illustrent ces principes avec élégance. Elles modélisent des séquences d’événements dont chaque étape dépend uniquement de l’état précédent, une propriété dite « sans mémoire ». Ce type de modèle simplifie les calculs tout en restant efficace pour anticiper des phénomènes variés, qu’il s’agisse de variations boursières, de reconnaissance vocale ou de parcours utilisateurs sur un site web. Néanmoins, la complexité du monde réel dépasse souvent le cadre d’une chaîne de Markov simple : des dépendances à long terme existent.
Pour les saisir, des modèles plus avancés, comme les réseaux de neurones récurrents (RNN) ou les Transformers, s’avèrent nécessaires pour intégrer le contexte global. Ces techniques ne se limitent pas à la théorie. La simulation stochastique, parfois brutale et gourmande en ressources informatiques, se révèle redoutablement efficace lorsque les solutions analytiques sont inaccessibles, offrant un outil puissant pour prédire et comprendre des systèmes complexes.
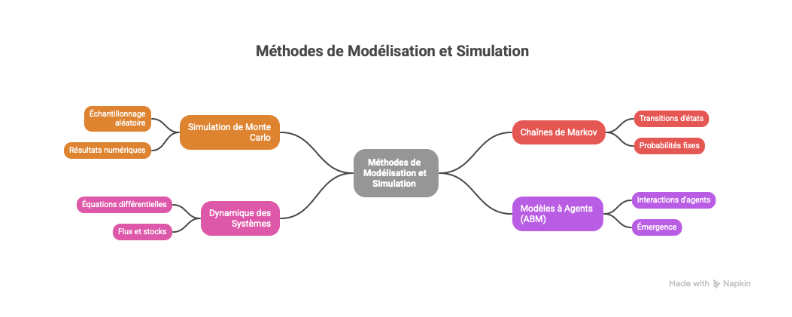
Comparaison des Méthodes de Simulation
| Méthode | Principe Fondamental | Complexité Computationnelle | Cas d’Usage Typique |
| Simulation de Monte Carlo | Échantillonnage aléatoire répété pour obtenir des résultats numériques. | Élevée (dépend du nombre d’itérations) | Finance, Physique des particules, Évaluation des risques. |
| Chaînes de Markov | Transitions d’états basées sur des probabilités fixes sans mémoire historique. | Moyenne | Modélisation du langage, Files d’attente, PageRank. |
| Dynamique des Systèmes | Utilisation d’équations différentielles pour modéliser les flux et les stocks. | Variable | Écologie, Économie macroscopique, Épidémiologie. |
| Modèles à Agents (ABM) | Simulation des interactions entre agents autonomes pour observer l’émergence. | Très Élevée | Sociologie computationnelle, Trafic urbain, Marchés financiers. |
Apprentissage automatique et analyse comportementale
L’apprentissage automatique permet d’identifier des schémas subtils et non linéaires dans le comportement humain en traitant de vastes ensembles de données, offrant la capacité de prédire les actions futures avec une précision statistique élevée. Cette aptitude à anticiper les décisions est au cœur de la science des données moderne. L’analyse comportementale via le Machine Learning dépasse la simple segmentation démographique. Ces modèles doivent être réentraînés en permanence.
Le comportement humain évolue avec les tendances culturelles, les saisons et le contexte économique. Science sociale computationnelle et dynamique de groupe La structure du réseau influence souvent plus la diffusion du message que son contenu. Les mesures de centralité (degré, proximité, intermédiarité) identifient les influenceurs clés, véritables ponts entre communautés. C’est une version numérique de la théorie des “liens faibles” de Granovetter, amplifiée par la puissance de calcul contemporaine.
Les simulations basées sur des agents (Agent-Based Modeling) permettent d’aller encore plus loin. Chaque agent suit des règles simples, par exemple : “si deux voisins adoptent une opinion, je l’adopte aussi.”
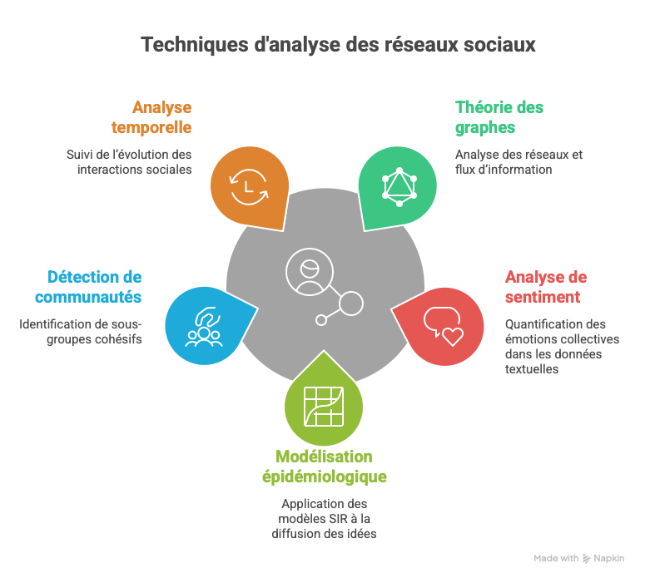
- Théorie des graphes : analyse des réseaux et flux d’information.
- Analyse de sentiment : quantification des émotions collectives dans les données textuelles.
- Modélisation épidémiologique : application des modèles SIR à la diffusion des idées.
- Détection de communautés : identification de sous-groupes cohésifs (algorithme Louvain).
- Analyse temporelle : suivi de l’évolution des interactions sociales.
Infrastructure Big Data et traitement en temps réel
L’architecture Big Data regroupe les technologies nécessaires pour ingérer, stocker et traiter des volumes massifs de données structurées et non structurées, avec une latence minimale. Sans cette base, l’analyse avancée reste théorique. Le stockage a lui aussi évolué. Les bases SQL traditionnelles peinent face à la variété et au volume des données non structurées. Les solutions NoSQL (Cassandra, MongoDB) et les Data Lakes (Hadoop, cloud) sont devenus standards. Mais un Data Lake mal géré devient rapidement un “Data Swamp” – un marécage de données inutilisables. La gouvernance, la qualité des métadonnées et la maintenance sont donc cruciales.
Les pipelines ETL/ELT sont le cœur du Data Engineering. Si les flux sont défaillants, les analystes en bout de chaîne ne peuvent rien produire de valeur. L’automatisation via des orchestrateurs comme Airflow garantit la fiabilité des flux, mais demande une vigilance constante : une mise à jour d’API peut perturber toute la chaîne.
Visualisation des données et interprétation cognitive
La visualisation transforme des ensembles de données complexes et des probabilités abstraites en représentations graphiques intuitives, facilitant l’interprétation des tendances et des risques. Une bonne visualisation raconte une histoire : elle met en lumière anomalies et patterns, et guide la prise de décision. Le cerveau humain reconnaît les motifs visuels mieux que les tableaux de chiffres, mais il est sensible aux biais. Une échelle tronquée ou un choix de couleurs inapproprié peut induire en erreur. L’éthique est donc essentielle.
Les techniques de réduction de dimensionnalité, comme t-SNE ou UMAP, permettent de projeter des données très hautes dimensions (embeddings, profils génétiques) dans un espace 2D ou 3D. Elles révèlent des clusters invisibles autrement, mais l’interprétation doit rester prudente : les distances projetées ne sont pas toujours proportionnelles à celles de l’espace original. L’interactivité est clé : zoom, filtres ou survol pour afficher des détails transforment une visualisation statique en outil exploratoire.
Éthique de l’IA et biais algorithmiques
Les cadres d’éthique en intelligence artificielle visent à garantir que les modèles prédictifs fonctionnent sans discrimination injuste, respectent la confidentialité des utilisateurs et restent transparents dans leurs processus décisionnels. Cet enjeu dépasse la simple technique et touche au juridique et au sociétal. La “boîte noire” des réseaux de neurones profonds pose également un défi de responsabilité. Si une banque refuse un prêt ou si un système médical émet un diagnostic basé sur une IA, il est crucial de pouvoir expliquer la décision.
L’explicabilité (Explainable AI, XAI) est un domaine en pleine expansion. Des outils comme SHAP (SHapley Additive exPlanations) permettent d’attribuer à chaque variable une contribution à la prédiction, rétablissant ainsi la confiance entre l’homme et la machine. Sans cette transparence, l’adoption de l’IA dans les secteurs critiques restera limitée par la méfiance légitime des utilisateurs et des régulateurs.
Réseaux de neurones et Deep Learning
Le Deep Learning utilise des architectures de réseaux de neurones à plusieurs couches pour modéliser des abstractions de haut niveau à partir de données brutes, surpassant souvent les méthodes traditionnelles dans les tâches de perception. Cette technologie est le moteur de la révolution actuelle en IA. Sa force réside dans l’apprentissage de représentations hiérarchiques.
Dans un réseau convolutif (CNN) traitant des images, les premières couches détectent des bords simples, les couches intermédiaires les assemblent en formes (yeux, roues, feuilles), et les couches finales identifient des objets complets. Cette structure s’inspire, dans une certaine mesure, du fonctionnement du cortex visuel biologique. En revanche, la quantité de données et la puissance de calcul nécessaires sont colossales : on parle de modèles comptant des milliards de paramètres, nécessitant des clusters de GPU fonctionnant pendant des semaines.
Les architectures évoluent rapidement. Après l’ère des CNN et RNN, les Transformers dominent désormais. Initialement conçus pour le traitement du texte, ils sont aujourd’hui utilisés en vision par ordinateur et dans l’analyse de séries temporelles. Leur mécanisme d’attention permet au modèle de hiérarchiser l’importance de chaque élément de l’entrée, quelle que soit sa distance, résolvant ainsi le problème de mémoire à long terme. Cette efficacité soulève néanmoins des questions environnementales : entraîner un grand modèle de langage consomme beaucoup d’énergie. La recherche se tourne donc vers des méthodes plus efficientes, comme le few-shot learning ou la distillation de modèles.
Types de réseaux de neurones et applications
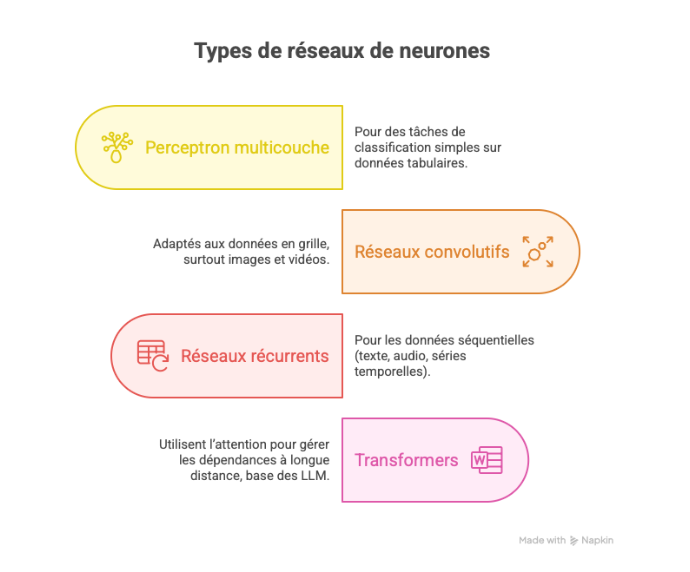
- Perceptron multicouche (MLP) : pour des tâches de classification simples sur données tabulaires.
- Réseaux convolutifs (CNN) : adaptés aux données en grille, surtout images et vidéos.
- Réseaux récurrents (RNN / LSTM) : pour les données séquentielles (texte, audio, séries temporelles).
- Transformers : utilisent l’attention pour gérer les dépendances à longue distance, base des LLM (Large Language Models).
- Autoencodeurs : pour réduction de dimension, débruitage et détection d’anomalies.
- GANs (Generative Adversarial Networks) : deux réseaux s’affrontent pour générer des données synthétiques réalistes (images, voix).
Conclusion et perspectives
L’analyse des données, l’apprentissage automatique et la science sociale computationnelle forment un triptyque indispensable pour comprendre la complexité du monde. Nous sommes passés d’une ère où la rareté des données posait problème à une ère où le défi est de trouver du sens au milieu du bruit. Les outils que nous avons évoqués, des chaînes de Markov aux réseaux de neurones profonds, ne sont pas des baguettes magiques, mais des instruments de précision nécessitant expertise et conscience éthique.
La modélisation stochastique rappelle que l’incertitude est inhérente à tout système dynamique, qu’il s’agisse de météo, de marchés financiers ou de comportements sociaux. L’avenir réside probablement dans l’hybridation : combiner modélisation causale et apprentissage automatique pour dépasser la corrélation et approcher les mécanismes de cause à effet. L’intégration de connaissances expertes dans les modèles data-driven pourrait renforcer robustesse et explicabilité.
Comme dans l’analogie des environnements probabilistes tels que les casinos, comprendre les lois du hasard et des grands nombres reste fondamental. Que l’on cherche à optimiser une logistique ou à analyser la propagation d’une idée, la rigueur mathématique associée à une analyse sociologique fine restera la clé pour transformer les données brutes en connaissances exploitables.